なぜ正規表現でURL判定してはいけないのか
JavaScriptでフォーム入力値のURLを検証したい場面が多くありますが、URL判定を正規表現だけで行うのは非常に危険です。
URLはRFC 3986およびWHATWG URL Standardで定義されており、とても複雑です。
- スキーム(http: など)
- ホスト(example.com)
- 認証情報(user:pass@)
- ポート番号
- クエリ文字列
- フラグメント
- IPv4 / IPv6
- IDN(日本語ドメイン)
- etc.
そのため、これらをすべて正規表現で判定するのはほぼ不可能で、できたとしても、かなり複雑なコードになってしまいます。
セキュリティ的に危険な正規表現による判定
次のような正規表現によるURL判定のコードをWeb上でよく見かけます。
JavaScript
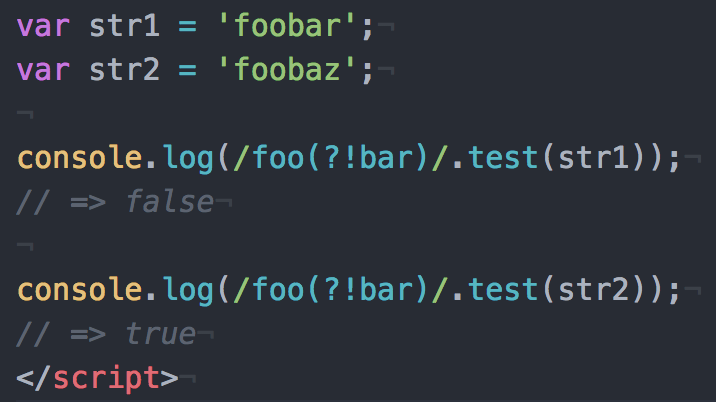
const isUrl = (url) => /^https?:\/\/.+$/.test(url)
console.log(isUrl('https://iwb.jp/')) // true
console.log(isUrl('iwb.jp')) // falseしかし、このようなコードは以下のような明らかにURLではない文字列もURLとして判定してしまうため、この判定だと問題が生じる可能性があります。
JavaScript
const isUrl = (url) => /^https?:\/\/.+$/.test(url)
console.log(isUrl(' https://iwb.jp/ ')) // false
console.log(isUrl('https:// ')) // true
console.log(isUrl('https://<script>')) // true
console.log(isUrl('https://テスト')) // true
console.log(isUrl('https://localhost:99999')) // trueURL判定はURLコンストラクタの使用を推奨
URL判定にはURLコンストラクタのnew URL()を使うことを推奨します。
以下のようにtry ... catch 文と併用することで、正確にURLを判定できます。
JavaScript
const isUrl = (url) => {
try {
const trimUrl = url.trim()
const parsed = new URL(trimUrl)
if (!/^[\u0000-\u007f]+$/.test(url)) return false
return /https?:/.test(parsed.protocol)
} catch {
return false
}
}
console.log(isUrl(' https://iwb.jp/ ')) // true
console.log(isUrl('https:// ')) // false
console.log(isUrl('https://<script>')) // false
console.log(isUrl('https://テスト')) // false
console.log(isUrl('https://localhost:99999')) // falseURLは前後にホワイトスペースがあっても「location.href = ' https://iwb.jp/ '」などのコードは通るので、JavaScriptの処理に使用するURLであれば trim() で除去しておいたほうが良いです。
また、「https://テスト」英語以外のドメインなどは通常はfalseにしたいケースが多いので、URLをASCIIのみか ^[\u0000-\007f]+$ の正規表現で判定しています。