絵文字の文字数カウント問題
絵文字は通常の文字とは異なり、JavaScriptで文字数をカウントする際には注意が必要です。
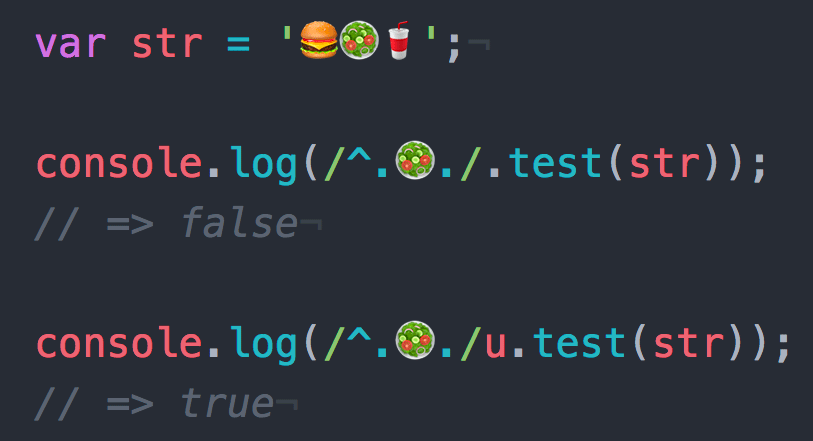
例えば、シンプルな方法である「'🤦🏻♂️'.length」を使っても、この絵文字の文字数は1ではなく7となり、正確にカウントできません。
'🤦🏻♂️'.length // 7
絵文字はサロゲートペアを組み合わせて作られている場合があります。
そのため、.lengthを使うと7文字のように2文字以上で判定されます。
【補足説明】 🤦 (U+1F926) - サロゲートペアとして2ユニット 🏻 (U+1F3FB) - サロゲートペアとして2ユニット [特殊文字] (U+200D) - 1ユニット ♂ (U+2642) - 1ユニット ︎[特殊文字] (U+FE0F) - 1ユニット これらを合計すると、🤦🏻♂️の絵文字は合計7ユニットとしてカウントされます。 したがって、JavaScriptで '🤦🏻♂️'.length を実行すると、結果は7になります。
絵文字を正確にカウントするには「emoji-regexライブラリ」または「Intl.Segmenter」を使用します。
emoji-regexライブラリのカウント方法
まず、以下のコマンドでemoji-regexをインストールします。
npm i -D emoji-regex
インストールしたらimportで読み込んで、replaceで絵文字をXに置換後に文字列をカウントします。
import emojiRegex from 'emoji-regex' const text = '🤦🏻♂️TEST🤦🏻' const replaceText = text.replace(emojiRegex(), 'X') console.log(replaceText.length) // 6
Intl.Segmenterのカウント方法
Intl.Segmenterで「granularity: "word"」を指定して各文字を1文字として処理できるようにします。
const text = '🤦🏻♂️TEST🤦🏻'
const segmeter = new Intl.Segmenter('ja-JP', { granularity: 'word'})
const result = text.map((t) => [...segmeter.segment(t)]).length
console.log(result) // 6
Intl.Segmenterのほうが、emoji-regexのnpm installが不要なので簡単に実装できますが、Firefoxで使えないというデメリットがあります。
そのため、Firefoxを対象とする場合はIntl.Segmenterの使用は避けたほうが良いです。