Node.jsでHTMLの要素取得
Node.jsを使用してWebサイトのHTML内の要素やテキストを調べて取得したいことがある。
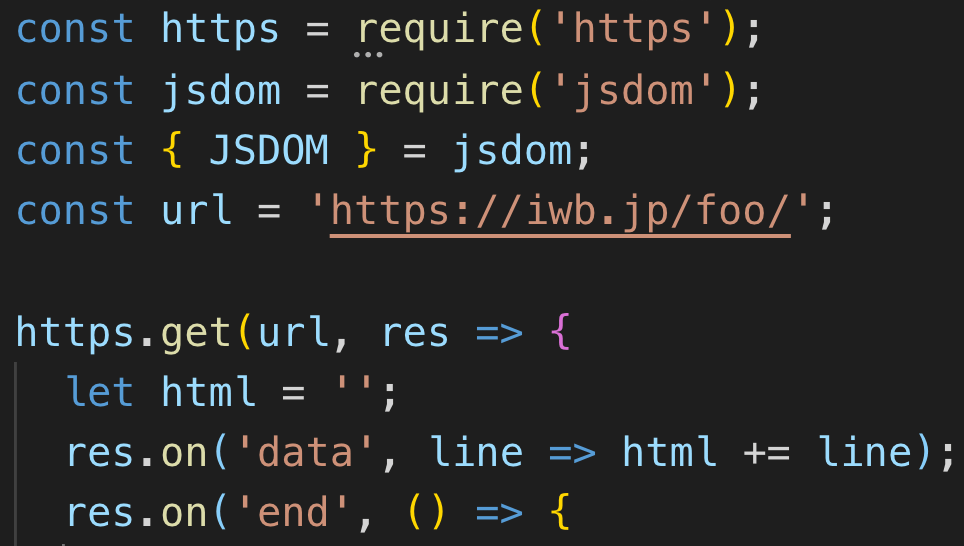
Node.jsはhttpsをrequireすれば簡単にHTMLを取得できる。(httpsのみ)
// sample.js
const https = require('https');
const url = 'https://iwb.jp/foo/';
https.get(url, res => {
let html = '';
res.on('data', line => html += line);
res.on('end', () => {
console.log(html);
});
});
node sample.js
結果をHTMLファイルで保存する場合は
node sample.js > sample.html
document.querySelectorを使いたい
単純にHTMLを取得するだけなら前述の方法で問題ないが、この方法だと例えば#item > li:last-childにあるテキストだけ取得するようなことはできない。
<!-- HTML例 --> <ul id="item"> <li>list1</li> <li>list2</li> <li>list3</li> </ul>
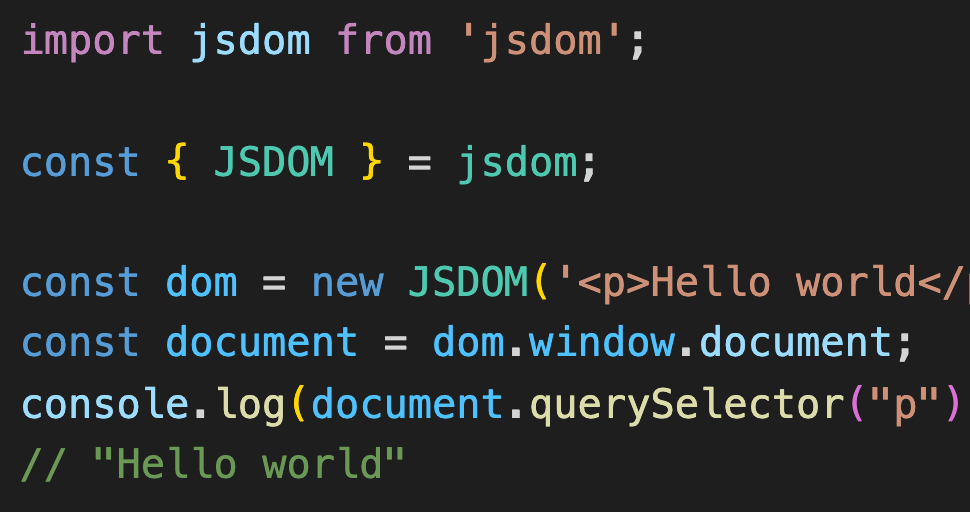
jsdomでdocument.querySelectorを使う
もしもdocument.querySelectorなどを使って特定の要素を指定したい場合はjsdomを使用する。
まず npm i jsdom でインストール。
その後requireで読み込んで以下のように記述するだけだ。
const https = require('https');
const jsdom = require('jsdom');
const { JSDOM } = jsdom;
const url = 'https://iwb.jp/foo/';
https.get(url, res => {
let html = '';
res.on('data', line => html += line);
res.on('end', () => {
const dom = new JSDOM(html);
console.log(dom.window.document.querySelector('#item > li:last-child').textContent);
// => list3
});
});
JavaScript実行後のHTMLを簡単に取得したい場合はPuppeteerなどを使用する必要がある