Puppeteerとは
Chromeを操って各種チェックなどを行えるようにするもの。
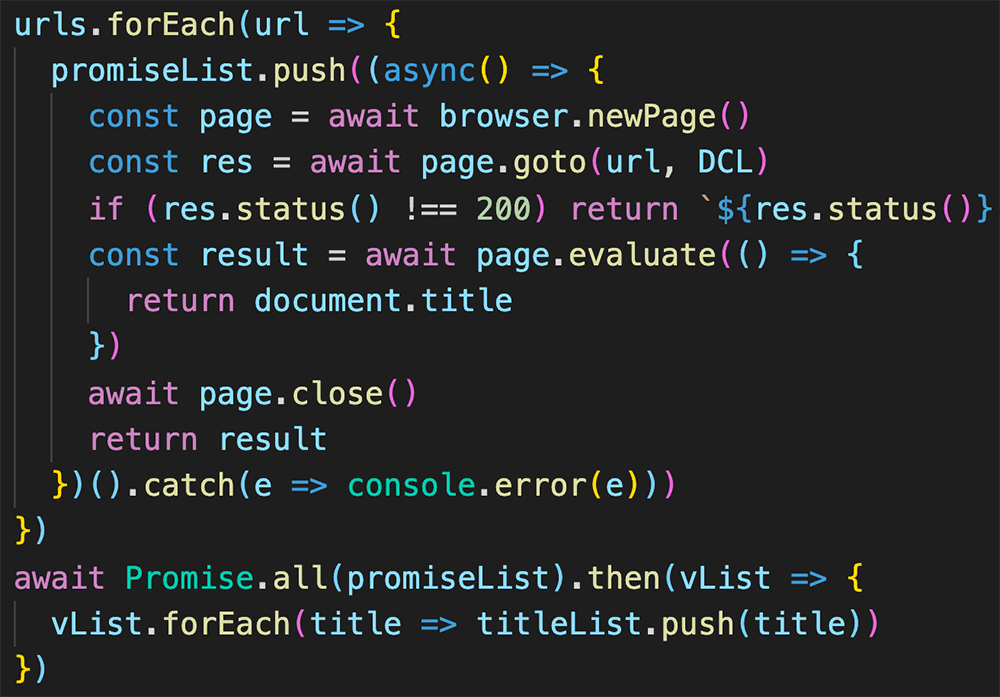
例えば下記のようなスクリプトを作成してnode test.jsを実行すればChromeが指定した文字列を検索して、さらにスクリーンショットを保存してくれる。
// test.js
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.google.co.jp/');
await page.type('#lst-ib', 'new date');
await page.waitFor(1000);
await page.click('.lsb');
await page.waitForNavigation();
await page.screenshot({path: 'screenshot.png'});
browser.close();
});

Puppeteerの意味と読み方
Puppeteerは「人形使い」という意味。人形使いのようにChromeを操るためこのような名称になっている。
読み方はパペティア
Puppeteerをブラウザ上で使用する方法
Try PuppeteerというPuppeteerをブラウザ上で使用できるサイトがある。
簡単な確認ならこれでできるができることが限られるので仕事には使えない。
https://try-puppeteer.appspot.com/
Puppeteerの使い方
Puppeteerを使用するにはNode.jsが必要なので入れていなければ公式サイトからインストールしておく。
インストールが完了したら下記のコマンドでPuppeteerをインストール。
$ npm i puppeteer
あとはtest.jsなどのJSファイルを作成してnode test.jsを実行すればPuppeteerが動作する。
ヘッドレスChromeを見える化
ヘッドレスChromeは画面上には表示されないが、launchにheadless: false, slowMo: 100のオプションを付けるとブラウザが起動して処理手順を確認できる。
headless: falseのときはpage.waitForNavigationは使用しないほうが良い。
const puppeteer = require('puppeteer');
puppeteer.launch({
headless: false,
slowMo: 100 // 遅延時間
}).then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.google.co.jp/');
await page.type('#lst-ib', 'new date');
await page.waitFor(1000);
await page.click('.lsb');
await page.screenshot({path: 'screenshot.png'});
browser.close();
});
iPhoneでの動作を確認する方法
Puppeteerはデバイスを指定してエミュレートできるため、例えばiPhone 5を指定してスクリーンショットを撮ることが可能。
デバイスをスマートフォンにすると表示されるサイトもスマートフォン用サイトになり、ページ内の要素が変わることがあるため注意が必要。
例えばGoogleの場合、入力フォームの部分はPCだと#lst-ibだがSPだと.gLFyfとなっている。
ちなみにフィーチャーフォン(ガラケー)サイトのチェックはPuppeteerではできない。
const puppeteer = require('puppeteer');
const devices = require('puppeteer/DeviceDescriptors');
const device = devices['iPhone 5'];
console.log(device);
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.emulate(device);
await page.goto('https://www.google.co.jp/');
await page.type('.gLFyf', 'new date');
await page.waitFor(1000);
await page.click('.Tg7LZd');
await page.waitForNavigation();
await page.screenshot({path: 'screenshot.png'});
browser.close();
});
フィーチャーフォンでスクリーンショット
スクリーンショットのみであればfp-scraperをインストールすれば可能だ。
$ npm i fp-scraper
const FpScraper = require('fp-scraper');
(async() => {
const scraper = new FpScraper({
urls: [
'http://www.google.co.jp'
],
outputDir: './fp-screenshot/',
cbSuccess: url => console.log(`Done: ${url}`),
cbError: url => console.log(`Error: ${url}`)
});
await scraper.scrape().then(() => {
console.log('END');
});
})();
フルスクリーンや特定の要素もスクリーンショット
フルスクリーンや特定の要素もスクリーンショットで撮ることができる。
lazyloadを使用した画像もfullPage: trueを付けるだけで撮影可能。
await page.screenshot({path: 'screenshot.png', fullPage: true});
特定の要素だけのスクリーンショットを撮りたい場合はDOM要素のスクリーンショットを撮るための関数を作成して指定する。
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.google.co.jp/');
await page.type('#lst-ib', 'new date');
await page.waitFor(1000);
await page.click('.lsb');
await page.waitForNavigation();
async function screenshotDOMElement(selector, padding = 0) {
const rect = await page.evaluate(selector => {
const element = document.querySelector(selector);
const {x, y, width, height} = element.getBoundingClientRect();
return {left: x, top: y, width, height, id: element.id};
}, selector);
return await page.screenshot({
path: 'screenshot.png',
clip: {
x: rect.left - padding,
y: rect.top - padding,
width: rect.width + padding * 2,
height: rect.height + padding * 2
}
});
}
await screenshotDOMElement('#searchform');
browser.close();
});
下記のように直接要素を指定してスクリーンショットは撮れない。
await page.$('#foo').screenshot({path: 'screenshot.png'});
さらに、pathがなければスクリーンショットは保存されない。
await page.$('#foo').screenshot();
スクリーンショット画像を1つに統合する
Puppeteerで保存した複数のスクリーンショットを1つに統合したいことがある。
Puppeteer自体には画像を統合する機能は存在しない。
そのため、画像を統合する際はImageMagickをインストールして下記のように記述して統合させる。
const puppeteer = require("puppeteer");
const im = require('imagemagick');
puppeteer.launch({
headless: false,
slowMo: 100
}).then(async browser => {
const page = await browser.newPage();
await page.goto("https://google.co.jp/");
async function screenshotDOMElement(selector, name, padding = 0) {
const rect = await page.evaluate(selector => {
const element = document.querySelector(selector);
const {x, y, width, height} = element.getBoundingClientRect();
return {left: x, top: y, width, height, id: element.id};
}, selector);
return await page.screenshot({
path: name + '.png',
clip: {
x: rect.left - padding,
y: rect.top - padding,
width: rect.width + padding * 2,
height: rect.height + padding * 2
}
});
}
const arr = ['foo', 'bar', 'baz'];
const convertArr = ['-append']; // 横結合は+append
for (const n of arr) {
await page.evaluate(n => {
return document.getElementById('lst-ib').value = n;
}, n);
await screenshotDOMElement('.tsf-p', n);
await convertArr.push(n + '.png');
}
await convertArr.push('result.png');
await im.convert(convertArr);
await browser.close();
});

imgタグの画像を保存する
Puppeteer自体には画像を保存する機能がないためfsを読み込んでsrcのパスを利用してダウンロードする。
const puppeteer = require('puppeteer');
const fs = require('fs');
const path = require('path');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.google.co.jp/');
const imageSrc = await page.evaluate(() => {
return document.querySelector('#lga img').src;
});
const fileName = imageSrc.split('/').pop();
const localPath = path.join(__dirname, fileName);
const viewSource = await page.goto(imageSrc);
fs.writeFile(localPath, await viewSource.buffer(), (error) => {
if (error) {
return console.log(error);
}
console.log(`ダウンロード完了: ${fileName}`);
});
await browser.close();
})();
PDFファイルを保存する
PuppeteerはgotoでpdfファイルのURLにアクセスできないため、PDFを保存するにはhttp.getを利用してダウンロードする。
const puppeteer = require('puppeteer');
const http = require('http');
const fs = require('fs');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.cyberagent.co.jp/ir/');
const pdfHref = await page.evaluate(() => {
return document.querySelector('.irp-title-block > a').href;
});
const fileName = fs.createWriteStream(pdfHref.split('/').pop());
http.get(pdfHref, res => {
res.pipe(fileName);
res.on('end', () => fileName.close());
});
await browser.close();
})();
page.clickを使用したときにページが遷移する場合はpage.waitForNavigationを記述しておくと遷移完了まで待ってくれる。
スクリーンショットを撮りたいときは必須。この場合、指定時間後に表示されているか不明瞭なpage.waitForは使用しないほうが良い。
await page.click('button');
await page.waitForNavigation();
await page.waitForNavigation();は文字数が多いので定数にして短くするのがおすすめ。
const NP = page.waitForNavigation(); await NP;
goto後にwaitForNavigationを指定しても意味がない。
この場合はgotoにwaitUntilのoptionを追加する。
// 間違った書き方
await page.goto('https://example.com/');
await page.waitForNavigation({ waitUntil: 'domcontentloaded' });
// 正しい書き方
await page.goto('https://example.com/', { waitUntil: 'domcontentloaded' });
waitUntil:'domcontentloaded'は使用頻度が高くPuppeteerの処理時間を向上できるため、定数に入れておくと良い。
また、waitUntil:'networkidle2'を使用すれば500ミリ秒間に2つ以上のネットワーク接続が存在しなければ処理を終了できるため、こちらのオプションも時間短縮になる。
gotoを使用する際は通常はHTMLだけ取得できている状態で終了しても良いのであればwaitUntil:'domcontentloaded'、画像やJSの読み込み後に終了するのであればwaitUntil:'networkidle2'を指定すると良いだろう。
const WUD = { waitUntil: 'domcontentloaded' };
const NK2 = { waitUntil: 'networkidle2' };
await page.goto('https://example.com/', WUD);
await page.goto('https://iwb.jp/', NK2);
clickのあとはwaitForSelectorも有効
clickのあとの要素がわかっているならwaitForSelectorを使用するとより確実に目的の要素を操作できる。
await page.click('button');
await page.waitForSelector('#foo .bar');
page.type使用時の注意点
page.typeは指定した要素に文字を入力するが、すでにvalueで文字が指定されている場合は語尾に追記してしまう。
例えば
に4を指定すると
になってしまう。
これを防ぐには下記のようにしてvalueを上書きする。
await page.$eval('#lst-ib', e => e.value = 'foo');
このようにinputのvalueを上書きする関数を作成しておくとコードの可読性が良くなる。
async function setInputVal(el, val) {
page.evaluate((data) => {
return document.querySelector(data.el).value = data.val;
}, {el, val});
}
await setInputVal('#lst-ib', 'val');
Cookieを設定する
page.setCookieでCookieを設定可能。(削除はdeleteCookie)
page.cookies()でCookieを取得可能
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.google.co.jp/');
await page.setCookie({"name": "foo", "value": "bar"});
const cookies = await page.cookies();
await console.log('cookies.json', JSON.stringify(cookies));
// await page.deleteCookie({"name": "foo"});
browser.close();
});
page.localStorage()はないため、localStorageに保存したい場合は、page.evaluateを使用する。
実行結果をfsでテキストファイルで保存
Puppeteer自体にはテキストファイルで保存する機能はないため、例えばCookieを取得してJSON形式で保存したい場合は以下のようになる。
const puppeteer = require('puppeteer');
const fs = require('fs');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.google.co.jp/');
const cookies = await page.cookies();
fs.writeFileSync('cookies.json', JSON.stringify(cookies));
browser.close();
});
page.evaluateとは
Puppeteerのコードを見ているとpage.evaluateというのをよく見かける。
page.evaluateはブラウザ内での実行結果を返す。
例えばlocalStrageを使用する場合はpage.evaluate内に処理を記述して返す。
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.google.co.jp/');
const data = await page.evaluate(() => {
let data;
localStorage.setItem('foo', 100);
data = localStorage.getItem('foo');
return data;
});
console.log(data); // => 100
browser.close();
});
headless: falseのときはpromptやalertも使用できるのでブラウザ上で一時停止して入力する文字列を指定したり、OKを押して次に進めるような使い方ができる。
ログイン画面の画像の文字認証は自動で入力することはできないため、promptが活躍する。
const puppeteer = require('puppeteer');
puppeteer.launch({
headless: false,
slowMo: 100
}).then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.google.co.jp/');
const t = await page.evaluate(() => prompt('検索する文字列を入力'));
await page.type('#lst-ib', t);
await page.click('.lsb');
await page.waitFor(1000);
await page.evaluate(() => alert('検索結果が表示されました'));
browser.close();
});
GoogleのreCAPTCHAのような画像を選択するタイプの場合はconfirmとwaitForを併用すると良いだろう。
const puppeteer = require('puppeteer');
puppeteer.launch({
headless: false,
slowMo: 100
}).then(async browser => {
const page = await browser.newPage();
await page.goto('https://iwb.jp/wp-login.php');
await page.$eval('#user_login', e => e.value = 'foo');
await page.$eval('#user_pass', e => e.value = 'bar');
const result = await page.evaluate(() => {
return confirm('認証のため5秒一時停止しますか?')
});
console.log(result); // true or false
if (result) {
await page.waitFor(5000);
}
browser.close();
});
nodeの引数を使用して値を入れる
Puppeteerはnodeで実行しているため、引数(process.argv[2])から検索用語を取得することもできる。
$ node sample.js foo
const puppeteer = require('puppeteer');
const searchWord = process.argv[2];
console.log('searchWord: ' + searchWord);
puppeteer.launch({
headless: false,
slowMo: 100
}).then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.google.co.jp/');
await page.type('#lst-ib', searchWord);
await page.click('.lsb');
await page.waitFor(5000);
browser.close();
});
page.goBackで前のページに戻る
前のページに戻るにはpage.gotoではなくpage.goBackを使用したほうが移動が早い。
ただし、SafariはChromeと違ってpage.goBack時にJavaScriptが実行されないので注意が必要。
SafariはChromeと違い戻るボタン後のページでJavaScriptが実行不可
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.google.co.jp/');
await page.type('#lst-ib', 'new date');
await page.waitFor(1000);
await page.click('.lsb');
await page.waitForNavigation();
await page.screenshot({path: 'screenshot.png'});
await page.goBack();
await page.screenshot({path: 'screenshot2.png'});
browser.close();
});
特定の要素のテキストを取得
特定の要素のテキストを取得するにはpage.$evalで要素を指定してinnerTextで取得する。(HTMLの場合はinnerHTML)
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://iwb.jp/');
const recentPost = await page.$eval('#recent-posts-2', e => e.innerText);
await console.log(recentPost);
browser.close();
});
JavaScriptでDOM変更前のHTML取得
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
const res = await page.goto('https://iwb.jp/');
const HTML = await res.text();
console.log(HTML);
browser.close();
});
特定のリンクの一覧を取得
Webサイト内の特定のリンクの一覧を取得する場合は下記の通りpage.$$evalを使用する。ちなみにpuppeteer.launch().thenで記述しない場合はこのようになる。
const puppeteer = require('puppeteer');
const url = 'https://iwb.jp/';
const target = '#recent-posts-2 > ul > li > a';
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
const links = await page.$$eval(target, links => {
return links.map((link) => link.href);
});
console.log('最近の投稿リンク一覧');
console.log(links.join('\n'));
await browser.close();
})();
要素の有無の確認
$evalや$$eval使用時に要素が存在しないとエラーになってしまうため、何かしらの理由でページ内に要素が存在しないことがある場合は以下の条件分岐で要素の有無を確認する必要がある。
if (await page.$('.foo')) {
await page.$$eval('.foo', c => c.value = 'bar');
}
page.$$はConsoleの$$とは異なる
ChromeのConsoleは$$('.wpp-list a')のような記述で要素すべてを指定して属性の値を取得できるがPuppeteerでpage.$$を同じように使用するとエラーになる。
// 下記のコードをiwb.jpで実行する
// Consoleでは実行可能
const a = $$('.wpp-list a');
a.forEach(v => console.log(v.href));
// Puppeteerで下記のコードはエラー
const a = page.$$('.wpp-list a');
a.forEach(v => console.log(v.href));
この場合はfor...of文でループさせてgetPropertyやjsonValueなどを使用して値を取得する必要がある。
const links = await page.$$('.wpp-list a');
for (let link of links) {
const a = await link.getProperty('href');
const href = await a.jsonValue();
console.log(href);
}
分割してrequireで読み込み
Puppeteerを使用してjsファイルの数が増えると共通しているコードが増えてくる。
共通している箇所は別ファイルにしてrequireで読み込めば再利用しやすい。
// CAST.js
module.exports.CAST = {
'ゴブリンスレイヤー': '梅原 裕一郎',
'女神官': '小倉 唯',
'妖精弓手': '東山 奈央'
};
// test.js
const { CAST } = require('./CAST.js');
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
console.log(CAST['女神官']);
// => 小倉 唯
await browser.close();
})();
パスワードなどはjs内に記述しない
パスワードなどをJavaScriptファイル内に記述すると当然ほかの人にも見られてしまう。
パスワードなどの他人に見られると困るものはコマンドライン上で渡す。
$ PWD=foobar node login.js
const puppeteer = require('puppeteer');
puppeteer.launch({
headless: false
}).then(async browser => {
const page = await browser.newPage();
await page.goto('https://ja-jp.facebook.com/login/');
await page.type('#email', 'mail@example.com');
await page.type('#pass', process.env.PWD);
});
引数が多くなければこのような書き方も可能。
$ node login.js foobar
const puppeteer = require('puppeteer');
puppeteer.launch({
headless: false
}).then(async browser => {
const page = await browser.newPage();
await page.goto('https://ja-jp.facebook.com/login/');
await page.type('#email', 'mail@example.com');
await page.type('#pass', process.argv[2]);
});
ただし、ターミナルなどで実行すると履歴が残るため、履歴を残したくない場合は上記の方法ではなくpromptを使用してブラウザ上でパスワードを入力したほうが良い。
JavaScript無効化で処理時間短縮
setJavaScriptEnabled(false)でJavaScriptを無効化すると処理時間を短縮できる。
無効化しても影響のないページなら無効化しておこう。
await page.setJavaScriptEnabled(false)