正規表現<a.*?</a>は間違い
はてなブックマークを見ていたら以下のような記事があった。
例えば、HTMLファイル内で1つの独立したアンカータグを検出したいときに、「<a.*</a>」と言った正規表現だと、最長一致を探してしまい、うまく行きません。(例えば、「<a href=”/home”>ホーム</a><a href=”/page”>ページ</a>」では、その文字列すべて(2つのアンカータグ)をマッチしてしまいます・・)
ここで、量指定子に「?」を付け加えて、最短一致でマッチさせれば、個々のアンカー要素を取り出すことができます。
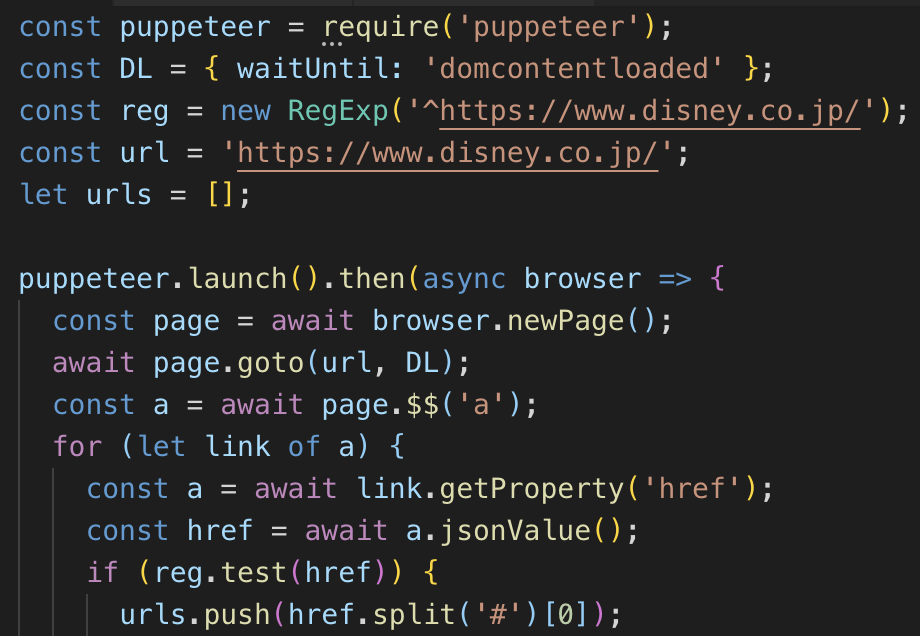
var re = new RegExp("<a.*?</a>");
var result = re.test('<a href="/">This is Target String</a>')
if (result) {
alert('マッチしました!');
}
…以上のような内容なのだったのだが、この正規表現は正しくない。
まず、new RegExp("<a.*?</a>")の部分なのだが「<a href=”/home”>ホーム</a><a href=”/page”>ページ</a>」の最短一致を探して検出するのであればgフラグが必要だ。
これがないと2つ目以降が検出されない。
// このように記述するのが正しい
// 内容によってはmフラグも必要なケースもある
var re = new RegExp("<a.*?</a>", "g");
さらに<a.*?</a>という正規表現だとaddressタグがある場合、これがマッチしてしまう。
正しいHTMLタグ正規表現
HTMLタグ正規表現はどのように書けば正しくマッチするのか。
答えは以下の通り
var re = /<a(?: .+?)?>.*?<\/a>/g;
なぜこれでaタグだけがマッチされるかというと、<a(?: .+?)?>の(?: .+?)?の部分が括弧部分の0か1回のマッチになり、0の場合は<a>のように属性なしのaタグをマッチし、1回の場合は<a .+?>と同じになり、属性ありのaタグがマッチされるためだ。
<a .+?>はaのあとに半角スペースが入っているため、この正規表現であればaddressなどのaタグ以外のタグがマッチされることはない。