複数のURLのステータスコードを調べるには
複数のURLのステータスコードを調べるにはconst urlsに調べるURLを入れてpage.gotoから_statusでステータスコードを取得する。
const puppeteer = require('puppeteer');
const DL = { waitUntil: 'domcontentloaded' };
const urls = [
'https://iwb.jp/s/foo.html',
'https://iwb.jp/s/bar.html',
'https://iwb.jp/s/404.html',
]
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
let len = urls.length;
for (const url of urls) {
const response = await page.goto(url, DL);
const result = len-- + '/' + urls.length + ' ' +
response._status + ' ' +
response._url;
console.log(result);
}
await browser.close();
});
aタグのリンクのステータスコードを調べる
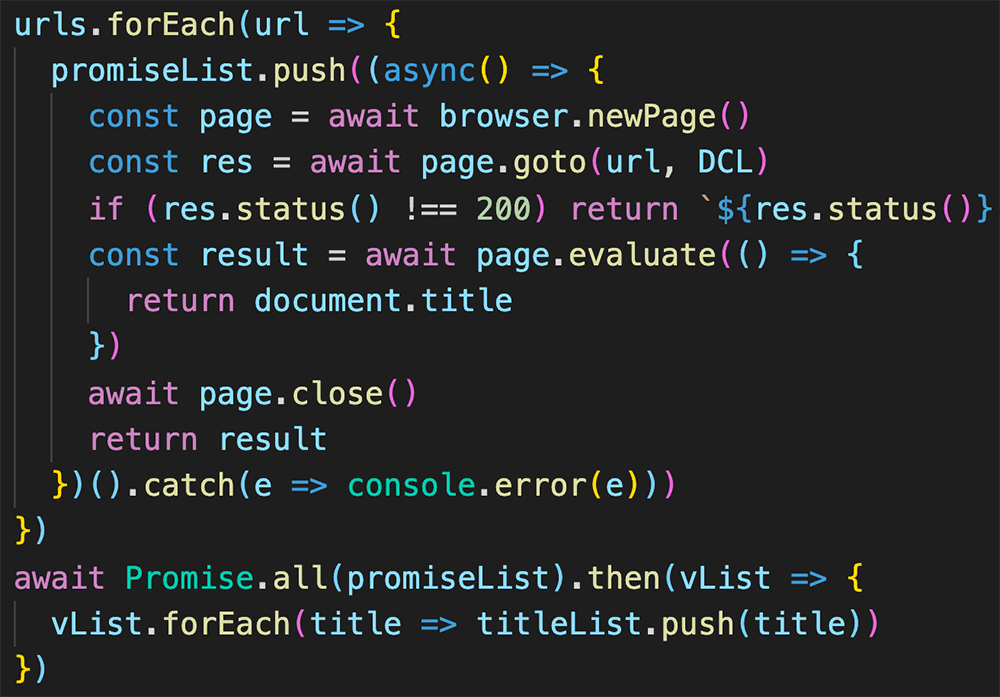
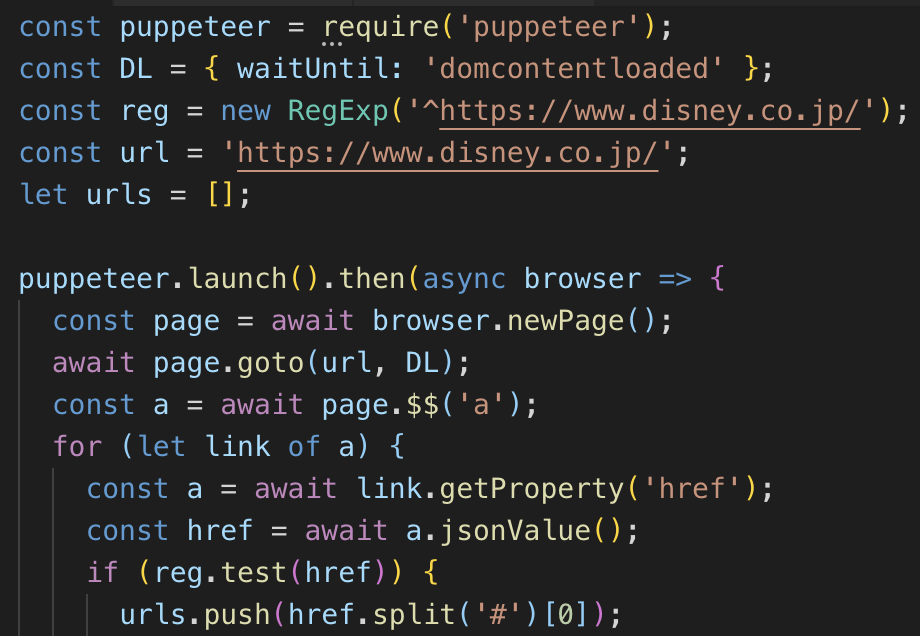
指定したURLのすべてンのaタグのステータスコードを調べるには以下のようになる。この場合はドメインで絞り込みも行ったほうが良いだろう。
aタグのすべてのurlをurlsの配列に入れたあとの処理は前述の処理と同じ。
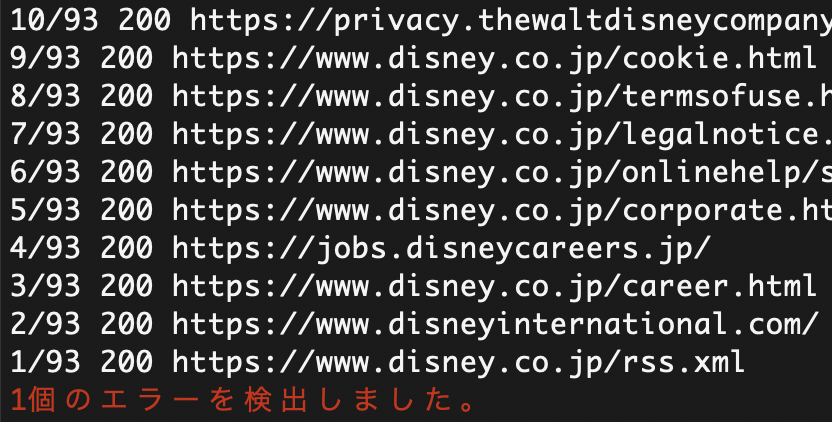
試しにdisney.co.jpのホームページで実行したら「アナと雪の女王 / 家族の思い出 オリジナル・サウンドトラック」がピエール瀧の影響で削除されて404になっていた。(2019年3月25日現在)
const puppeteer = require('puppeteer');
const DL = { waitUntil: 'domcontentloaded' };
const reg = new RegExp('^https://www.disney.co.jp/');
const url = 'https://www.disney.co.jp/';
let urls = [];
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto(url, DL);
const a = await page.$$('a');
for (let link of a) {
const a = await link.getProperty('href');
const href = await a.jsonValue();
if (reg.test(href)) {
urls.push(href.split('#')[0]);
}
}
urls = urls.filter((x, i, c) => c.indexOf(x) === i);
let len = urls.length;
for (const url of urls) {
const response = await page.goto(url, DL);
const result = len-- + '/' + urls.length + ' ' +
response._status + ' ' +
response._url;
console.log(result);
}
await browser.close();
});
pageerrorイベントでエラー検知
404ではないが、page.on('pageerror', 〜を使用すればページ内のエラー検知も可能になるので404チェックの際は記述しておくと良いだろう。
page.on('pageerror', e => console.log(e.message));
responseイベントで404検知
responseイベントを使用すればpage.gotoで開いているページのresponseをすれば取得できる。
取得の際にresponse.status() >= 400の条件を追加すれば問題のあるステータスコード400番台以上のログだけをすべて表示することができる。
page.on('response', res => {
if (res.status() >= 400) {
console.error(res.status(), res.url())
}
});