Puppeteerとは
以前「PuppeteerによるヘッドレスChromeの使い方 evaluate」という記事を書いたのだが、現在ではコードが古くなってまともに動作しなくなってしまったので「PuppeteerによるヘッドレスChromeの使い方 2021年度版」を新たに作成した。
PuppeteerとはChromeを操ってWebスクレイピングを行い各種チェックなどができるNodeライブラリ。
例えば下記のようなスクリプトを作成してnode test.jsを実行すればChromeが指定した文字列を検索して、さらにスクリーンショットを保存してくれる。
// test.js
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.google.co.jp/');
await page.screenshot({path: 'screenshot.png'});
browser.close();
});
使用するにはまずNode.jsの推奨版をインストールする。
Node.jsをインストールしたら適当なフォルダを作成してcdで移動したあとnpm init -yを実行後、任意のJSファイル(サンプルではtest.js)というファイルを作成してnpm i -D puppeteerでPuppeteerをインストールしたあとにnode test.jsのコマンドで実行する。
mkdir sample cd sample npm init -y touch test.js npm i -D puppeteer node test.js
Puppeteer実行中にChromeを表示
デフォルトの設定だとヘッドレスChromeは画面上には表示されないが、launchにheadless: false, slowMo: 100などのオプションを付けるとブラウザが起動して処理手順を確認できる。
slowMoは実行速度をミリ秒で指定するオプション。
const puppeteer = require('puppeteer');
puppeteer.launch({
headless: false,
slowMo: 100 // 遅延時間
}).then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.google.co.jp/');
await page.type('[name="q"]', 'new date');
await page.waitForTimeout(100);
await page.click('[type="submit"]');
await page.waitForNavigation();
await page.screenshot({path: 'screenshot.png'});
browser.close();
});
Puppeteerの処理時間短縮
page.gotoなどは第2引数にwaitUntil: domcontentloaded または networkidle2 を指定すると処理時間を短縮できる。
domcontentloadedはHTML文書の読み込みと解析が完了したら終了。
networkidle2はコネクション数が2以下になってから500ms続いたら終了。
domcontentloadedのほうが処理は早いがCSS, JS, 画像などの読み込み完了も必要なら後者のnetworkidle2を指定したほうが良い。
const DCL = { waitUntil: 'domcontentloaded' };
const NK2 = { waitUntil: 'networkidle2' };
await page.goto('https://example.com/', DCL);
await page.goto('https://example.net/', NK2);
JavaScript無効化で処理時間短縮
setJavaScriptEnabled(false)でJavaScriptを無効化すると処理時間を短縮できる。
無効化しても影響のないページなら必ずbrowser.newPage()の直下に追記したほうが良い。
const page = await browser.newPage();
await page.setJavaScriptEnabled(false);
iPhoneでの動作を確認する方法
Puppeteerはデバイスを指定してエミュレートできるため、例えばiPhone 6を指定してスクリーンショットを撮ることが可能。
const puppeteer = require('puppeteer');
const device = puppeteer.devices['iPhone 6'];
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.emulate(device);
await page.goto('https://www.example.com/');
await page.screenshot({path: 'screenshot.png'});
browser.close();
});
フルスクリーンのスクリーンショット
フルスクリーンショットを保存したいときはpage.screenshotにfullPage: trueを追加する。
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.yahoo.co.jp/');
await page.screenshot({
path: 'screenshot.png',
fullPage: true,
});
browser.close();
});
特定の要素の範囲をスクリーンショット
特定の要素の範囲をスクリーンショットを保存したいときはpage.screenshotのclipに範囲を指定する。
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.yahoo.co.jp/');
const rect = await page.evaluate(() => {
const target = document.querySelector('#Topics');
const _rect = target.getBoundingClientRect();
return {
x: _rect.left,
y: _rect.top,
width: _rect.width,
height: _rect.height,
};
});
await page.screenshot({
path: 'screenshot.png',
clip: rect,
});
browser.close();
});
スクリーンショット画像を1つに統合
スクリーンショット画像を1つに統合したい場合はnpm i imagemagickでインストールしてimagemagickを使用して下記のような処理で統合する。
const puppeteer = require('puppeteer');
const im = require('imagemagick');
puppeteer.launch({
headless: false,
slowMo: 100
}).then(async browser => {
const page = await browser.newPage();
await page.goto('https://google.co.jp/');
async function screenshotDOMElement(selector, name, padding = 0) {
const rect = await page.evaluate(selector => {
const element = document.querySelector(selector);
const {x, y, width, height} = element.getBoundingClientRect();
return {left: x, top: y, width, height, id: element.id};
}, selector);
return await page.screenshot({
path: name + '.png',
clip: {
x: rect.left - padding,
y: rect.top - padding,
width: rect.width + padding * 2,
height: rect.height + padding * 2
}
});
}
const arr = ['foo', 'bar', 'baz'];
const convertArr = ['-append']; // 横結合は+append
for (const n of arr) {
await page.evaluate(n => {
return document.querySelector('[name="q"]').value = n;
}, n);
await screenshotDOMElement('#searchform', n);
await convertArr.push(n + '.png');
}
await convertArr.push('result.png');
await im.convert(convertArr);
await browser.close();
});
imgタグの画像の保存方法
Puppeteer自体には画像を保存する機能がないためfsを読み込んでsrcのパスを利用してダウンロードする。
const puppeteer = require('puppeteer');
const fs = require('fs');
const path = require('path');
const DCL = { waitUntil: 'domcontentloaded' };
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.setJavaScriptEnabled(false);
await page.goto('https://www.google.co.jp/', DCL);
const imageSrc = await page.evaluate(() => {
return document.querySelector('#lga img').src;
});
const fileName = imageSrc.split('/').pop();
const localPath = path.join(__dirname, fileName);
const viewSource = await page.goto(imageSrc);
fs.writeFile(localPath, await viewSource.buffer(), (error) => {
if (error) {
return console.log(error);
}
console.log(`ダウンロード完了: ${fileName}`);
});
await browser.close();
})();
PDFファイルの保存方法
PuppeteerはgotoでPDFファイルのURLにアクセスできないため、PDFを保存するにはhttps.getを利用してダウンロードする。
const puppeteer = require('puppeteer');
const https = require('https');
const fs = require('fs');
const DCL = { waitUntil: 'domcontentloaded' };
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://www.cyberagent.co.jp/ir/', DCL);
const pdfHref = await page.evaluate(() => {
return document.querySelector('.irp-title-block > a').href;
});
const fileName = fs.createWriteStream(pdfHref.split('/').pop());
https.get(pdfHref, res => {
res.pipe(fileName);
res.on('end', () => fileName.close());
console.log('PDFのダウンロード完了');
});
await browser.close();
})();
Cookieを設定する
page.setCookieでCookieを設定可能。(削除はdeleteCookie)
Cookieの取得はpage.cookies()で実行する。
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.example.com/');
await page.setCookie({"name": "foo", "value": "bar"});
const cookies = await page.cookies();
await console.log('cookies.json', JSON.stringify(cookies));
// await page.deleteCookie({"name": "foo"});
browser.close();
});
page.localStorage()はないため、localStorageに保存したい場合は、page.evaluateを使用する。
page.evaluateとは
Puppeteerのコードを見ているとpage.evaluateというのをよく見かける。
page.evaluateはブラウザ内での実行結果を返す。
例えばlocalStrageを使用する場合はpage.evaluate内に処理を記述して返す。
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.example.com/');
const data = await page.evaluate(() => {
let data;
localStorage.setItem('foo', 100);
data = localStorage.getItem('foo');
return data;
});
console.log(data); // => 100
browser.close();
});
headless: falseのときはpromptやalertも使用できるのでブラウザ上で一時停止して入力する文字列を指定したり、OKを押して次に進めるような使い方ができる。
ログイン画面の画像の文字認証は自動で入力することはできないため、promptが活躍する。
const puppeteer = require('puppeteer');
puppeteer.launch({
headless: false,
slowMo: 100
}).then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.google.co.jp/');
const t = await page.evaluate(() => prompt('検索する文字列を入力'));
await page.type('[name="q"]', t);
await page.click('[type="submit"]');
await page.waitForTimeout(1000);
await page.evaluate(() => alert('検索結果が表示されました'));
browser.close();
});
GoogleのreCAPTCHAのような画像を選択するタイプの場合はconfirmとwaitForTimeoutを併用すると良いだろう。
const result = await page.evaluate(() => {
return confirm('認証のため5秒一時停止しますか?')
});
console.log(result); // true or false
if (result) {
await page.waitForTimeout(5000);
}
Basic認証からログインする
ログインのIDとパスワードがWebページ内ではなくBasic認証のダイアログから入力が必要な場合はpage.authenticateであらかじめ設定しておけばログインできる。
await page.authenticate({
username: 'kakarot',
password: 'ueXshitaBLYRA'
});
nodeの引数を使用して値を入れる
Puppeteerはnodeで実行しているため、引数(process.argv[2])から検索用語を取得することもできる。
$ node sample.js foo
const puppeteer = require('puppeteer');
const searchWord = process.argv[2];
console.log('searchWord: ' + searchWord);
if (!searchWord) return;
puppeteer.launch({
headless: false,
slowMo: 100
}).then(async browser => {
const page = await browser.newPage();
await page.goto('https://www.google.co.jp/');
await page.type('[name="q"]', searchWord);
await page.click('[type="submit"]');
await page.waitForTimeout(3000);
browser.close();
});
page.goBackで前のページに戻る
前のページに戻るにはpage.gotoではなくpage.goBackを使用したほうが移動が早い。
await page.goBack();
titleタグの内容を取得する
console.log(await page.title());
metaタグの内容を取得する
console.log(await page.$eval('head > meta[name="description"]', el => el.content));
特定の要素のテキストを取得
特定の要素のテキストを取得するにはpage.$evalで要素を指定してtextContentで取得する。(HTMLの場合はinnerHTML)
const text = await page.$eval('body', e => e.textContent);
await console.log(text);
JavaScriptでDOM変更前のHTML取得
const puppeteer = require('puppeteer');
puppeteer.launch().then(async browser => {
const page = await browser.newPage();
const res = await page.goto('https://example.com/');
const HTML = await res.text();
console.log(HTML);
browser.close();
});
特定のリンクの一覧を取得
Webサイト内の特定のリンクの一覧を取得する場合は下記の通りpage.$$evalを使用する。
const puppeteer = require('puppeteer');
const url = 'https://iwb.jp/';
const target = '#recent-posts-2 > ul > li > a';
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
const links = await page.$$eval(target, links => {
return links.map(link => link.href);
});
console.log('最近の投稿リンク一覧');
console.log(links.join('\n'));
await browser.close();
})();
特定のliタグの一覧を取得
PuppeteerではliタグのHTMLを取得したいことがよくある。
そんなときもpage.$$evalを使用すれば簡単に取得できる。
const puppeteer = require('puppeteer');
const url = 'https://iwb.jp/';
const target = '#recent-posts-2 > ul > li';
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
const links = await page.$$eval(target, links => {
return links.map(link => link.outerHTML);
});
console.log(links);
await browser.close();
})();
page.$$evalではなくpage.$$でも同様のことができる。
page.$$を利用してforで回して2だけ取得したい場合などに使える。
const puppeteer = require('puppeteer');
const url = 'https://iwb.jp/';
const target = '#recent-posts-2 > ul > li';
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(url);
const list = await page.$$(target);
let datas = [];
for (let i = 0; i < 2; i++) {
datas.push(await (await list[i].getProperty('outerHTML')).jsonValue())
}
console.log(datas);
await browser.close();
})();
要素の有無の確認
$evalや$$eval使用時に要素が存在しないとエラーになってしまうため、何かしらの理由でページ内に要素が存在しないことがある場合は以下の条件分岐で要素の有無を確認する。
if (await page.$('h1')) {
console.log('ページ内にh1があります。');
} else {
console.log('ページ内にh1がありません。');
}
分割してrequireで読み込み
Puppeteerを使用してjsファイルの数が増えると共通しているコードが増えてくる。
共通している箇所は別ファイルにしてrequireで読み込めば再利用しやすい。
// CAST.js
module.exports.CAST = {
'桜衣乃': '新田ひより',
'関野ロコ': '久保田梨沙',
'貫井はゆ': '白石晴香'
};
// test.js
const { CAST } = require('./CAST.js');
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
console.log(CAST['関野ロコ']);
// => 久保田梨沙
await browser.close();
})();
CSSにstyleを追加
モーダルやアコーディオンなどはdisplay: none;で非表示になっている場合があるので、そんなときはdiplay: block;やCSSのclassの追加などで表示させる。
await page.$eval('.modal', el => el.style.display = 'block');
await page.$eval('.modal', el => el.classList.add('show'));
フォームの入力とクリック
await page.type('[name="q"]', 'JS');
await page.click('[type="submit"]');
フォームやリンクをclickしたあとの遷移先でも何か処理をする場合はページ遷移が完了してから処理されるよう必ずpage.waitForNavigationまたはpage.waitForSelectorを追記したほうが良い。
const DCL = {waitUntil: 'domcontentloaded'};
await page.click('[type="submit"]');
await page.waitForNavigation(DCL);
// await page.waitForSelector('.foo');
フォームのvalueの取得
await page.$eval('[name="q"]', el => el.value);
フォームのselectタグの選択
await page.select('select[name="year"]', '2020');
フォームの送信
送信ボタンをpage.clickでもできるがformが1つであればpage.evaluateを利用してsubmit()で送信したほうが簡単。
await page.evaluate(() => $('form').submit());
Promise.allによる並列処理
複数のURLにアクセスしてWebスクレイピングする場合は普通にforなどで順に処理するよりもPromise.allを使用して並列処理したほうが早くなる。
Promise.allを使用して大量のURLを処理することはできないので注意。
const startTime = Date.now()
const puppeteer = require('puppeteer')
const DCL = {waitUntil: 'domcontentloaded'}
const urls = [
'https://yahoo.co.jp/',
'https://line.me/ja/',
'https://mixi.jp/',
'https://dena.com/jp/',
'http://gree.jp/',
];
(async() => {
const browser = await puppeteer.launch()
const promiseList = []
const titleList = []
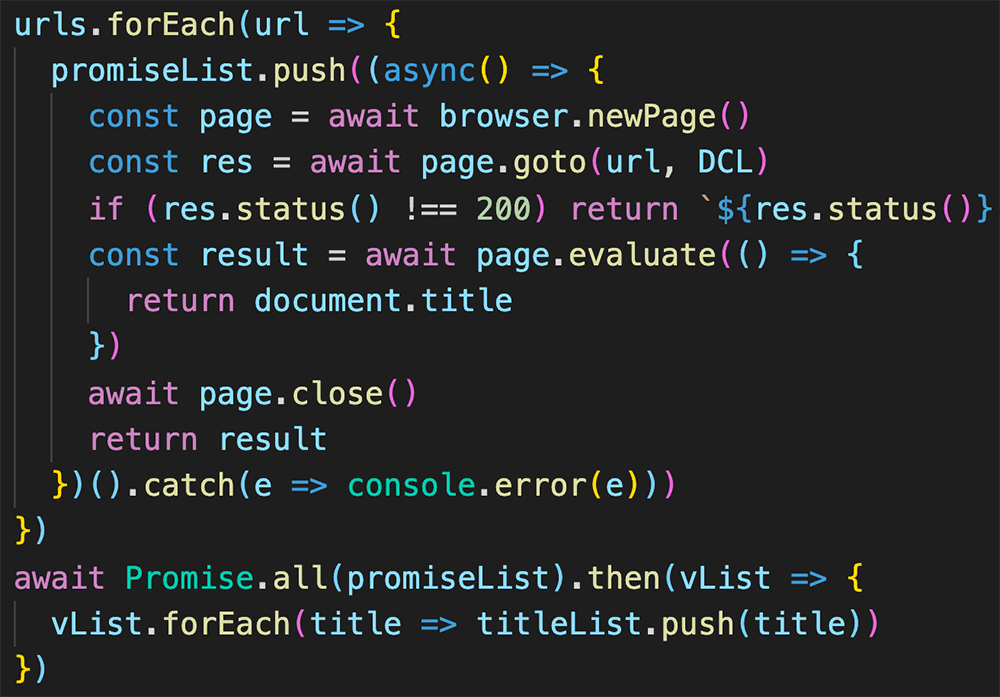
urls.forEach(url => {
promiseList.push((async() => {
const page = await browser.newPage()
const res = await page.goto(url, DCL)
if (res.status() !== 200) return `${res.status()} ERROR`
const result = await page.evaluate(() => {
return document.title
})
await page.close()
return result
})().catch(e => console.error(e)))
})
await Promise.all(promiseList).then(vList => {
vList.forEach(title => titleList.push(title))
})
console.log(titleList)
await browser.close()
console.log(Math.round((Date.now() - startTime) / 1000) + '秒')
// => 2秒
})()