連番(番号)は推測されやすい
Webサイトによってはフォルダやファイル名に連番が使用されていることがある。
連番といってもfoo1, foo2のようなもの以外にも200131, 200201... のような連続した数字ではないが推測されやすい日付の数字をフォルダ名やファイル名につけているサイトも見かける。
このような法則性のある命名規則だと公開前にサーバーにアップすると法則性がバレるとサーバーサイドで対策をしていなければ順番にURLを確認されることでステータスコードからファイルの有無がバレる恐れがある。。
※ 以降のやり方はサーバーに負荷がかかるので、自分のサーバー以外でやるのは非推奨です。
ステータスコードからファイルの存在を検出
前述の説明を見ても、「推測されやすいといってもランダムな8桁の数字あれば大丈夫だろう」と考える人もいるかも知れない。
結論から言うと大丈夫ではない。
おそらくそういう人はブラウザのアドレスバーから1つずつURLを入れて試すことを想定していると思うが、こういうのはシェルスクリプトというプログラムを使用すれば簡単に検出できてしまう。
例えば下記のようにanimal1.png, animal2.pngがある場合は…
http://iwb.jp/s/eto/animal1.png
http://iwb.jp/s/eto/animal2.png
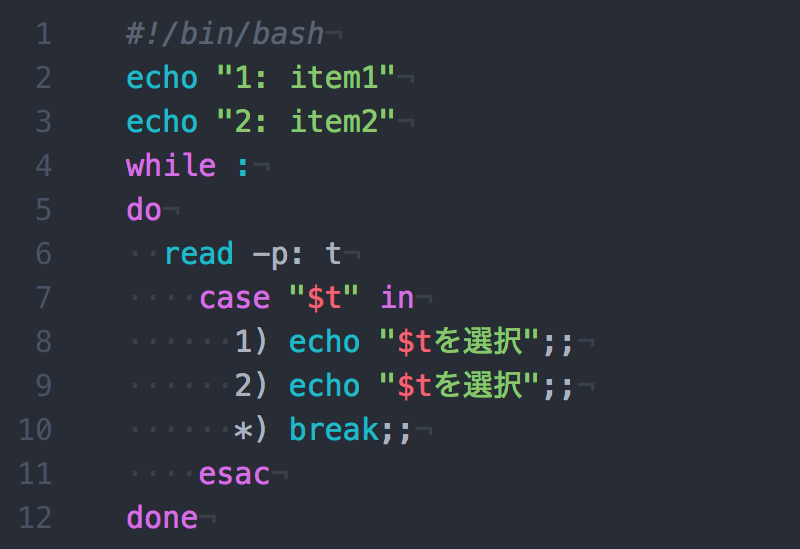
このようにシェルスクリプトで0から9をfor文で繰り返せば他の存在するファイルも簡単にわかる。
# res.sh # touch res.csvで事前にファイルを作成済み for ((i=0 ; i<10 ; i++)) do url=http://iwb.jp/s/eto/animal$i.png echo -n "$url," >> res.csv curl -I $url | head -1 >> res.csv done
書き出されたres.csvはこちら。
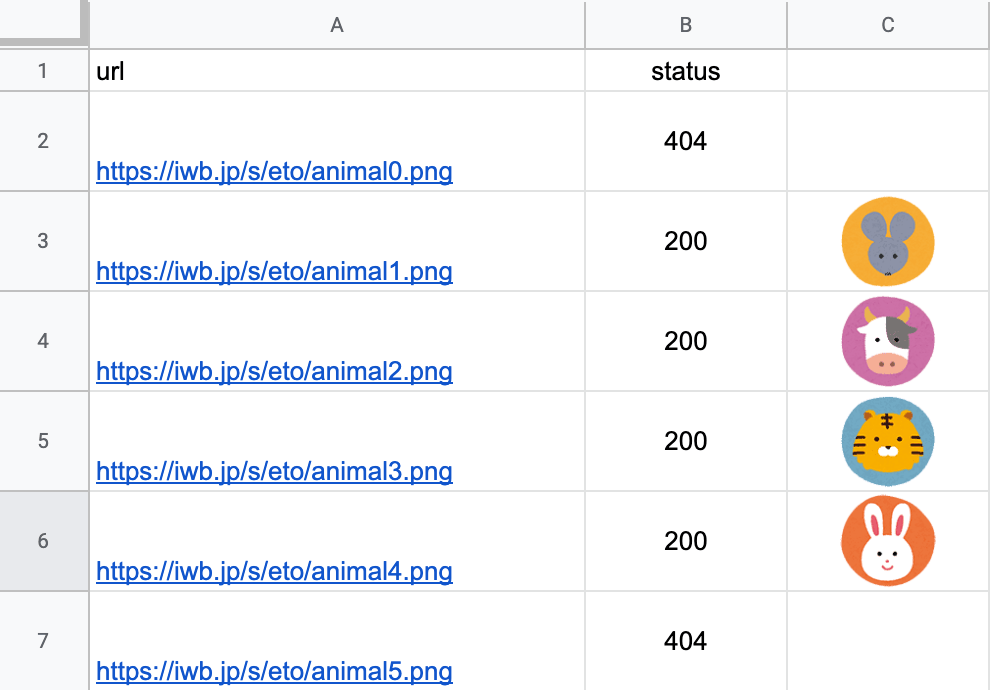
ファイルの中身を見ると、1から4はステータスコードが200で存在していることがわかり、それ以外は404なので存在しないことが一目瞭然。
url,status http://iwb.jp/s/eto/animal0.png,HTTP/1.1 404 Not Found http://iwb.jp/s/eto/animal1.png,HTTP/1.1 200 OK http://iwb.jp/s/eto/animal2.png,HTTP/1.1 200 OK http://iwb.jp/s/eto/animal3.png,HTTP/1.1 200 OK http://iwb.jp/s/eto/animal4.png,HTTP/1.1 200 OK http://iwb.jp/s/eto/animal5.png,HTTP/1.1 404 Not Found http://iwb.jp/s/eto/animal6.png,HTTP/1.1 404 Not Found http://iwb.jp/s/eto/animal7.png,HTTP/1.1 404 Not Found http://iwb.jp/s/eto/animal8.png,HTTP/1.1 404 Not Found http://iwb.jp/s/eto/animal9.png,HTTP/1.1 404 Not Found
GoogleスプレッドーシートのGASでも独自関数を作成するが同じようなことができるが、速度は遅くなる。
しかし、IMAGE関数でURLの画像をセル内で表示可能なので画像確認ができるというメリットがある。
function getStatus(url) {
var res = UrlFetchApp.fetch(url, { muteHttpExceptions:true });
return res.getResponseCode();
}
対策方法は?
フォルダまたはファイル名に数字ではなくランダムな英数字を使用する。
英数字であれば5000兆を超える組み合わせも簡単に作成可能だし推測されにくいため安全です。